資料集簡述:winequality-red.csv內為1599筆不同的紅酒規格,包含:"fixed acidity";"volatile acidity";"citric acid";"residual sugar";"chlorides";"free sulfur dioxide";"total sulfur dioxide";"density";"pH";"sulphates";"alcohol",並依規格對每個樣品進行quality分級(低至高:1~9)
資料會先預處理並依等級分別標上good(quality>6)、median(quality==6)、bad(quality<6),然後將資料及分割為Training Set與Test Set兩份,最後使用SVM來進行分類(Classification)學習並預測Test Set。
SVM(Support Vector Machine)簡述:
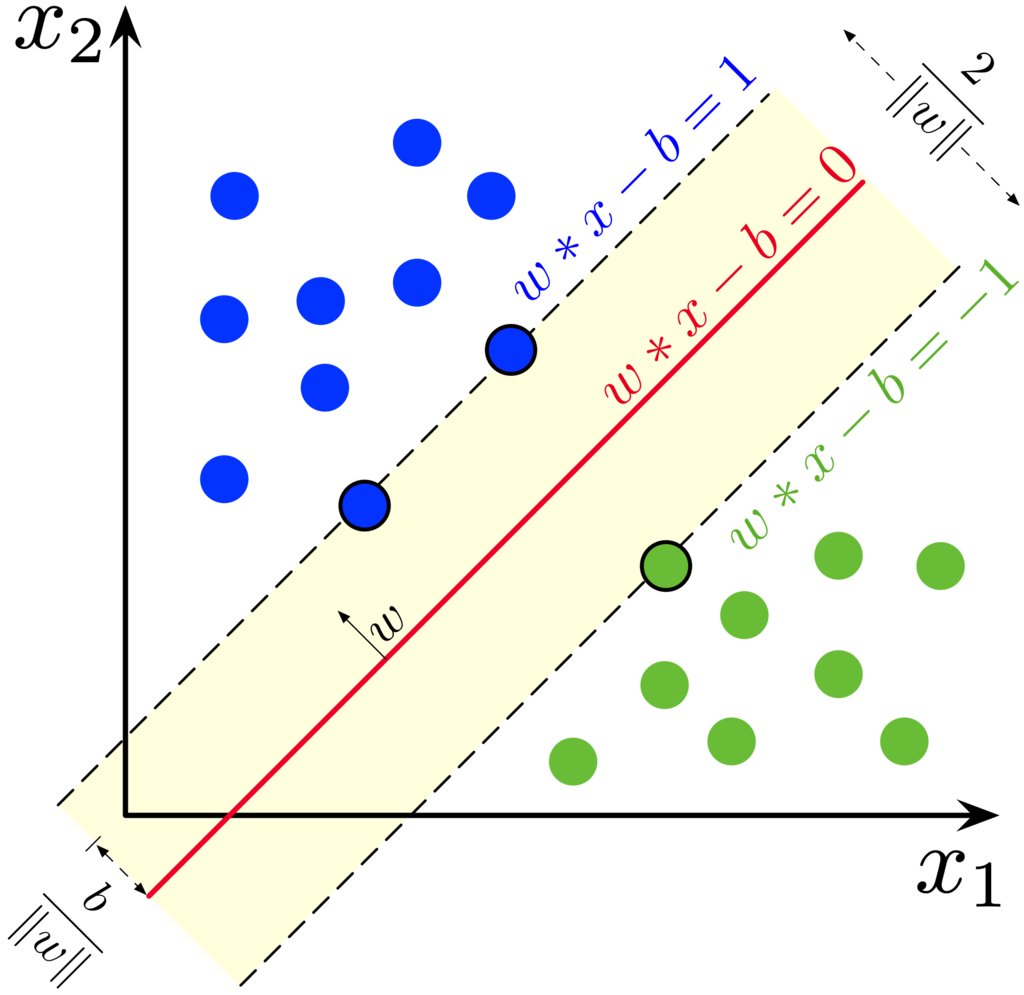
SVM是監督式學習(supervised learning)的一種。簡單說,其目的為找出不同類別的之間最佳的分界線(下圖紅實線),使邊際(Margin, 黑虛線)至分界線的距離w最大化,進而找到最佳的classifier,而落在邊際(黑虛線)的點,稱之為支撐向量(Support Vestors,如下圖藍色兩點綠色一點,以黑框線標記)。下圖是二維時的範例,如果變成三維那classifier就變成了一個面,維度繼續增加至超過3維也都適用。Classifier亦可以為線性或非線性,下圖只是最簡單的範例。
 |
| 來源:wikipedia |
 |
| 來源:djinit.ai |
SVM在python的套件sklearn中,可用在二元分類、多元分類及迴歸分析等,高維度的資料也適用。我個人的經驗是,SVM很直覺,且可應用在大多數的問題上,在python的操作也不難,是很實用的工具。當然SVM也有許多缺點,並不是所有問題都是直接套進去跑完了就沒事,之後有時間再寫一篇各算法的優缺點比較。



程式碼
1. 第一步是把所有會用到的套件全部載入
- pandas、numpy是最基本存取並處理資料的兩個套件
- sklearn.svm中的SVC是最簡單的SVM
- sklearn.decomposition import PCA as RandomizedPCA 用於找出真正重要的features並除掉多餘(insignificant)的features.
- pipeline是scikit-learn的一個強大功能,我的理解是它可以用於串起Sklearn中的多種算法,並使用簡單的幾行code來完成程式。下面會詳述
- GridsearchCV為:創建一組需要被"比較"的參數設定(argument),而後在訓練學習中找出最佳參數組合。GridsearchCV訓練並比對完成後會自動套入表現(performance)最佳的參數並直接建模(modeling),相當實用
*資料讀取略過
- 用pandas中的.DataFrame()建立一欄填滿序號0~1588(numpy.arange(0,length()))的空白表格'rate',用於存放for迴圈中的三種分類
- wine['rate']=rate 用於在wine表格最後面新增一欄
- .iloc[]是用於存取pandas dataframe物件的函數,格式為[row, column]
3. 將原始資料分為Training及Test

 重點來了
重點來了
- 載入train_test_split套件,
- 公式為:y= b0+b1X1+b2X2+.....,y是要預測的['rate'],X是features
- Xtrain, Xtest, ytrain, ytest可自行命名,train_test_split()會依此順序將分好的資料依序存入命名的物件中
- Training 跟 Test 的分割,預設是test_size = 0.25,可以自行更改,參考。
- RandomizePCA(n_components=6, whiten=True),主成份分析,功能是是降維,原始資料是11維,有些維度可能是不重要的,透過PCA把它們去除掉。n_components是最後我們至少要留下多少維度,先隨便設為6
- SVC就是SVM。kernel設定為非線性'rbf' (線性則設為'linear'),因為是多元分類問題(rate有三個等級),因此decision_function_shape設為'ovo'。更多參數設定請參考
- 最後使用make_pipeline()將兩個模型串在一起,並命名為model。之後我們只要呼叫model,便可同時操作兩個在內的模型。這邊的設定概念是:pca選出顯著的features後,再將其送到SVC進行分類學習,就像工廠的產線一樣,「生出」最後的模型。
- 在for迴圈中,跑1~10個pca最佳主成份數目,並用GridsearchCV()依次跟'svc_C'及'svc_gamma'兩個SVC中的重要參數搭配,找出最佳準確率的參數組
- svc_C是SVM中的重要參數,c越高margin越「硬」,反之越軟。
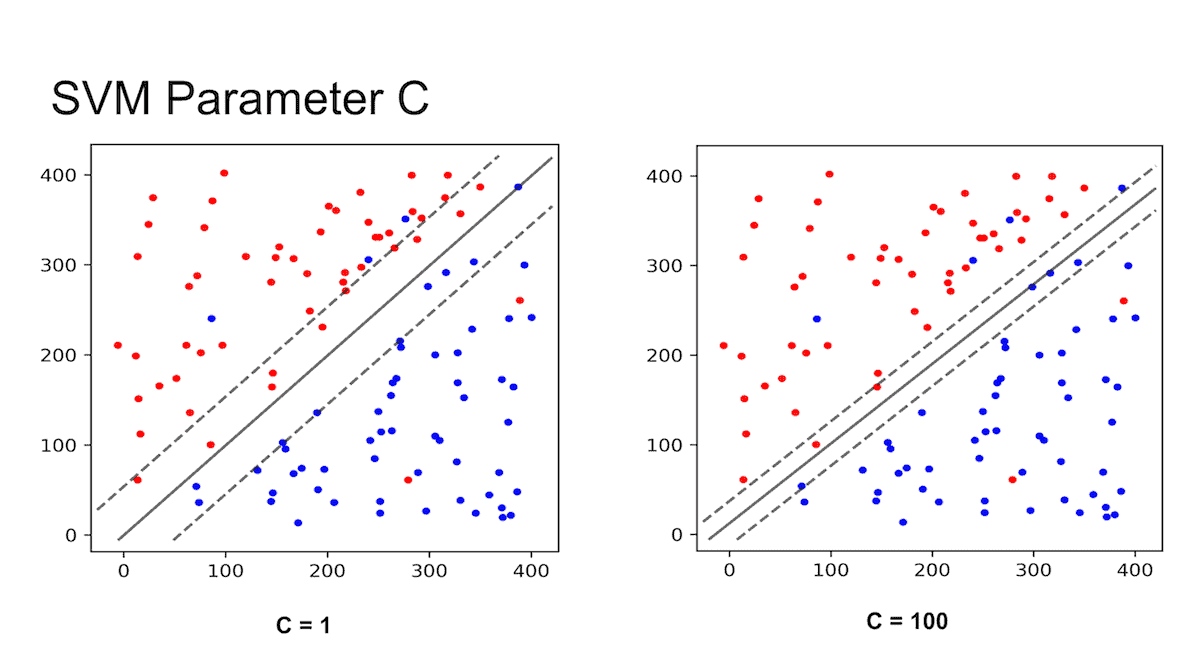
6. 訓練結果

- 第五步找出的最佳參數C=100, gamma=0.005, pca = 10(全部features都很重要的意思),代入空模型
- make_pipeline()建立空模型model
- 用.fit(x, y) 將訓練資料代入空模型進行訓練
- .predict(Xtest)將測試資料代入
- 計算訓練時間及準確率
*註:pandas物件可以直接進行print()中,sum()這樣的操作,直接計算預測等級跟實際等級相同的列數
沒有留言:
張貼留言